10 Benefits of Custom Software for Your Business – Fewer Resources, Greater Efficiency
Dedicated software is an investment that increases company efficiency, minimizing IT resource consumption and supporting a sustainable development strategy.
 Author:
Author:In the previous article, we started taking a closer look at artificial neural networks, specifically, we discussed the functioning of a trained model for classification tasks. Today we’ll delve into the process of training itself: what it is, its stages, and what each of them involves. Let’s get started!
Classification using neural networks is an example of supervised learning (if you’re not familiar with this term, we encourage you to check out the second article in the ML series). Before we even get to the training of a suitable model for a chosen task, it’s essential to have a substantial dataset with labelled examples. For example, continuing with the animal family recognition problem (mammal, reptile, amphibian) mentioned in the previous article, to train an appropriate model, we should have, say, 5000 labelled samples representing each family.
Once we’ve gathered this dataset, we can split it into three parts:
Now, we’re ready to start the actual training procedure.
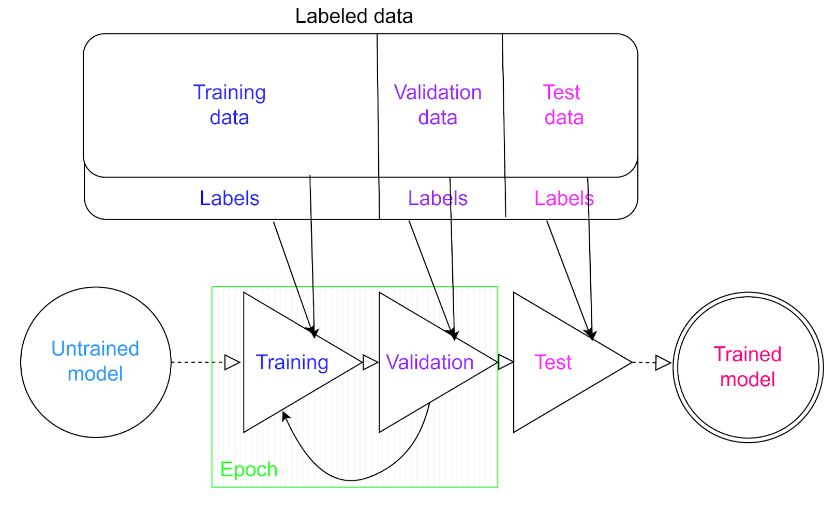
Fig. 1: An example scheme of neural network training procedure. Source: ML course 2023, Natalia Potrykus
The training procedure consists of several steps performed in a loop:
One complete iteration of steps 1-2 is called an epoch.
After completing the procedure described above, it’s time to use the third part of the dataset, the test set. We use it in the same way as the validation set during each epoch. The only difference is in the purpose of this use. The purpose of validating the model (step 2 in the list above) is to check how well the model handles “unknown” data, which means data that wasn’t used in training but can reveal how well the model generalizes.
Imagine having 1000 training samples and setting the number of training epochs quite high, like 500. Additionally, you have 150 test samples, and you decide to skip the validation step entirely.
You observe the training progress and notice that with each epoch, the model becomes more accurate at recognizing the training samples. By the end of the training, the model achieves nearly 99.99% accuracy on the training data, which seems nearly perfect!
Feeling confident, you test the model, and to your surprise, the model’s accuracy on the 150 test samples is around 75%. What happened? Was 500 epochs not enough?
While there’s a teeny-tiny chance that this might be true, it’s unlikely. What you’re witnessing is an effect known as overfitting, which means the model has fit the training data excessively. As a result, the model can perfectly recognize the data used in training, but its generalization abilities are poor. The validation process aims to detect the point at which the model begins to perform worse on new data, and it’s where you should stop the training.
For the example described, if you had implemented validation and plotted the results, it might look like this:
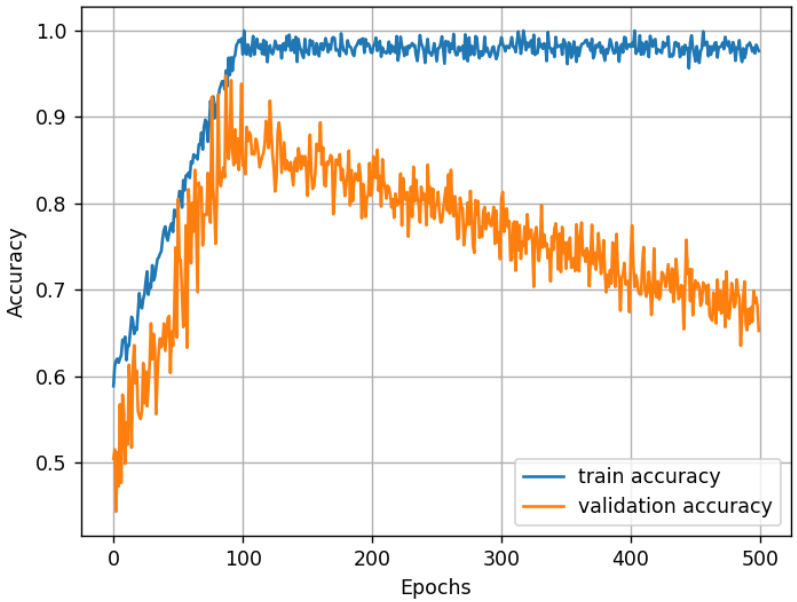
Fig. 2: Training accuracy (in blue) and validation accuracy (in orange). The graph clearly shows that after around 100 epochs, the model starts overfitting.
This chart clearly shows that after about 100 epochs, the model begins to show signs of overfitting. This would be the right time to stop the training.
It’s essential to remember that, although it’s rare to achieve as high accuracy on the test or validation set as on the training set, closely monitoring the training progress can help you make the most of your model.
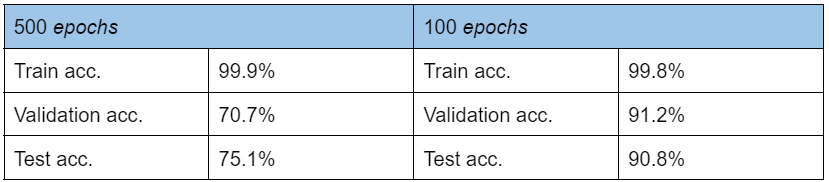
Tab. 1: Comparison of training, validation and test accuracy over 500 and 100 epochs.
The lesson from today’s discussion is straightforward: in training, as in life, moderation is essential! That’s all from us for today. We’ll be back in a week, and we’ll dive deeper into the operations that occur within the structure of a neural network during one training epoch. Stay tuned!

10 Benefits of Custom Software for Your Business – Fewer Resources, Greater Efficiency
Dedicated software is an investment that increases company efficiency, minimizing IT resource consumption and supporting a sustainable development strategy.
Green IT

Responsible Software Development: How to Reduce Your Application’s Carbon Footprint?
Practical tips on how developers can actively reduce CO2 emissions by optimizing code, infrastructure, and application architecture.
Green ITInnovation

Green IT: How Technology Can Support Environmental Protection?
An introduction to the idea of Green IT – a strategy that combines technology with care for the planet.
Green ITInnovation