Helm for the Second Time – Versioning and Rollbacks for Your Application
We describe how to perform an update and rollback in Helm, how to flexibly overwrite values, and discover what templates are and how they work.
 Author:
Author:In this article, as Innokrea, we want to describe to you the basics of clean code. Clean code is an approach in object-oriented programming that involves the use of a set of principles, thanks to which the generated code becomes more transparent, coherent and thus safer. Why? Because it is easier for programmers to work with, catch errors or simply understand its logic.
What are the benefits of the clean code approach?
The primary advantage is that by being familiar with the principles of clean coding, we become better programmers, and thus make it easier for other team members or companies to work. Another very important argument is that using these principles allows us to prevent a situation where our code is so inconsistent and poorly designed that fixing errors is much more time-consuming, and sometimes even impossible in a reasonable time. Code that is not clear and self-explanatory can disorient, cause frustration and extend the time it takes to understand class logic and their repair, as well as increase application failure rates. Poor code architecture approach will result in the appearance of three more errors in place of one after the expansion of functionality or their modification, which will require programmers to make additional efforts to make the program work. Therefore, it can be noticed that a good approach to writing code can save us a lot of time later and increase the efficiency of work on application development in the longer term. Adding more classes to bad code increases our technological debt, which will have to be paid someday. So what are the basic principles of clean code?
Significant Names
We will start with what may seem like the simplest, yet one of the fundamental principles of writing clean code – naming. Names play a fundamental role in programming. We name almost everything from variables to classes, functions, arguments, or files. Therefore, it is worth considering how to approach naming in a neat and transparent way.
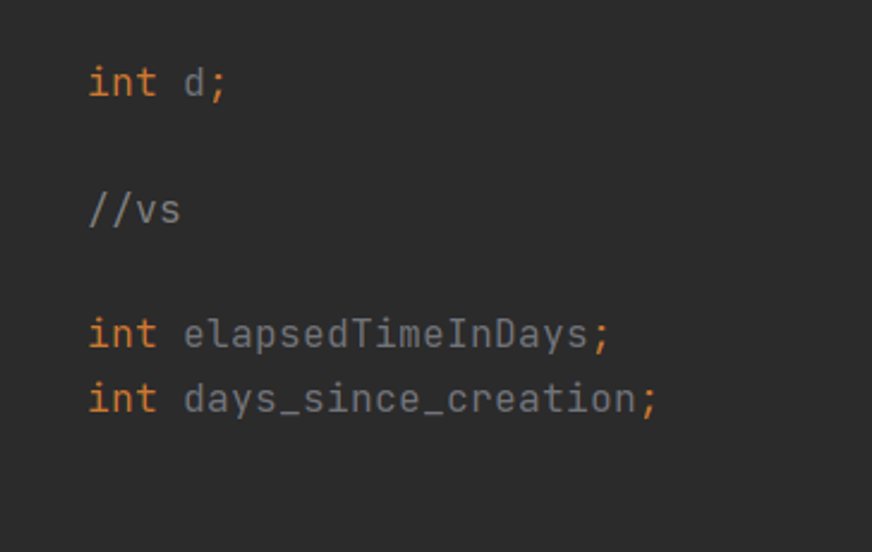
Figure 1: Incorrect naming convention vs. correct naming convention
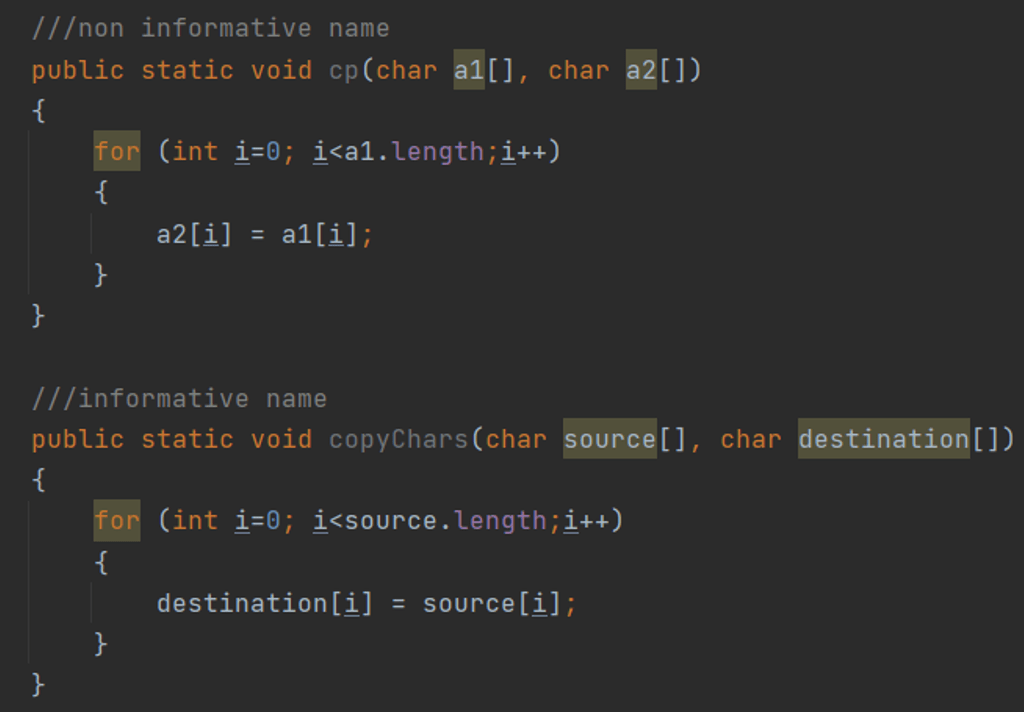
Figure 2: Both the function name and arguments are not informative
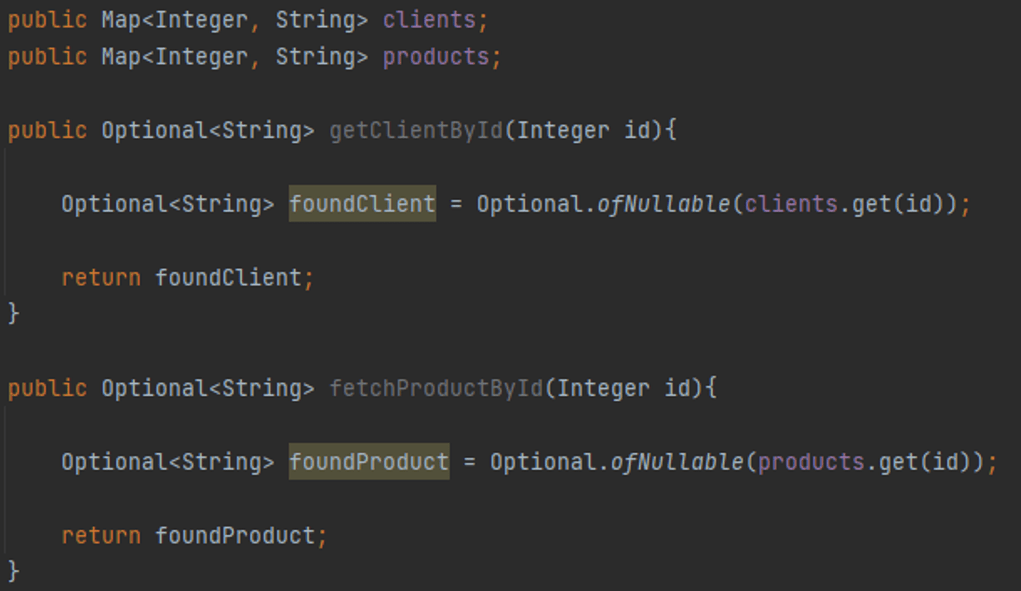
Figure 3: Example of inconsistent naming of methods in a class
Functions
An essential aspect of creating functions is their size – they should be as small as possible. The maximum size of a well-written function is about 20 lines. It should also perform only one operation and work at a single level of abstraction. This means that we should not create a function that reads data from a file and displays it in a browser at the same time. More than one operation is performed here, and one level of abstraction is not maintained.
It is also good practice to place our functions according to the descending principle, i.e., so that the programmer “reading from top to bottom” goes down to lower levels of abstraction. For example: we have a function for creating PDF files, it uses methods that add metadata to the file and content to the document. According to the descending principle, we first place the main function, and then the ones it uses. This allows us to maintain the order of abstraction levels and code clarity.
As for function arguments, the maximum recommended number is 2 or 3 – the fewer, the better. A single argument function is easier to understand than a multi-argument function. The latter is even more troublesome when it comes to unit testing, where writing all test scenarios for arguments can be cumbersome. Similarly, you should not use flag arguments, i.e., those that condition the function’s operation. For example, a Boolean passed, which depending on its value changes which operations will be performed.
Comments
First, let’s talk about how comments should not be used. One of the basic principles is that bad code should not be commented out, but rather fixed. There is a tendency to use such practice, which leads to the fact that over time the comment “ages” and may introduce misleading suggestions. Precise and clear code with a small number of comments is better than cluttered code with lots of comments. Similarly, if our functions and variables require describing their meaning, it means that we did something wrong regarding the first point discussed in this article. Names should be precise and expressive enough to express our intentions without using comments.
However, there are cases where using comments is justified:
Comments can describe what a regex is matched to. This will make work easier not only for us, but also for other programmers.

Figure 4: Comment describing the format validated by a given regex
Comments can warn that a function is not thread-safe or is deprecated.

Figure 5: Comment suggesting the use of another function
“TODO” comments can be used to leave information about what needs to be done, but for some reason cannot be done at this time. Remember not to use this type of comment as an excuse for leaving bad code.
Code formatting
Finally, let’s look at the rules of formatting. When working with code, it is good to choose a set of simple formatting rules and stick to them. If we join a team, we should adhere to the prevailing style without introducing additional confusion. It is also worth familiarizing ourselves with good practices that almost every language or technology has. For example, Java recommends using Camel Case notation where the function name will look like getUserByName(). On the other hand, Python proposes Snake Case, where the same function name will be written as get_user_by_name(). We also suggest paying attention to code indentation. If we nest one instruction inside another, we should indent.
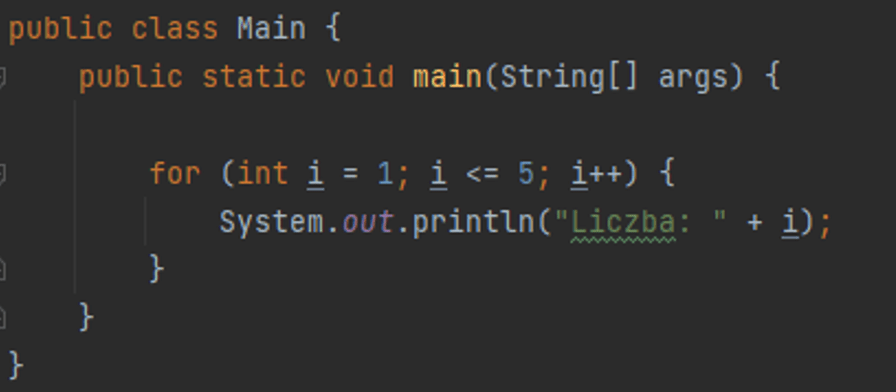
Figure 6: Using indentation in code
Summary
We hope that the basic principles presented by us will inspire you to change your approach and direct you towards producing much cleaner and more transparent code that will make work easier for both you and others. Code quality and transparency are of tremendous importance for its safety. If this topic interests you, we recommend the book “Clean Code” by Robert C. Martin and the sources below. Remember that without practice, perfect code will not write itself!
Sources:
https://garywoodfine.com/what-is-clean-code/
https://betterprogramming.pub/12-conventions-for-writing-clean-code-e16c51e3939a
https://www.pluralsight.com/blog/software-development/10-steps-to-clean-code
https://medium.com/swlh/the-must-know-clean-code-principles-1371a14a2e75

Helm for the Second Time – Versioning and Rollbacks for Your Application
We describe how to perform an update and rollback in Helm, how to flexibly overwrite values, and discover what templates are and how they work.
AdministrationInnovation
Helm – How to Simplify Kubernetes Management?
It's worth knowing! What is Helm, how to use it, and how does it make using a Kubernetes cluster easier?
AdministrationInnovation

INNOKREA at Greentech Festival 2025® – how we won the green heart of Berlin
What does the future hold for green technologies, and how does our platform fit into the concept of recommerce? We report on our participation in the Greentech Festival in Berlin – see what we brought back from this inspiring event!
EventsGreen IT