Responsible Software Development: How to Reduce Your Application’s Carbon Footprint?
Practical tips on how developers can actively reduce CO2 emissions by optimizing code, infrastructure, and application architecture.
 Author:
Author:In today’s article, we finish with the cryptography series and begin a series of posts about machine learning—a field that is currently advancing at an incredible pace and permeating virtually every sector of the economy (and the field of computer science itself). Furthermore, it can be risked to say that today, all the most advanced IT systems are supported by solutions from this branch of science.
It must be said clearly—although the field offers immense possibilities for applications and often greatly facilitates the work of companies or researchers, before jumping into the world of machine learning (ML) technologies in business, one should seriously consider and analyze the financial, human and technical resources of the company. Sometimes, using machine learning is not the best (or even – not a profitable) choice. Why? We will try to answer this question while introducing some characteristics of this approach and providing an overview before delving deeper into the topic.
Many of the commonly used machine learning techniques today require large sets of high-quality samples to start with. Sometimes, this alone can be a significant problem—especially in situations involving sensitive data with limited access. Of course, collecting, let’s say, hundreds of thousands of images containing human faces may not be a problem in some cases. However, most popular methods today, classified as supervised learning, such as neural networks or decision trees, require additional annotations of the data. These annotations are typically much harder, more time-consuming, and costly to obtain. For example, a neural network that recognizes facial contours from an image requires presenting it with thousands, tens of thousands, or even hundreds of thousands (depending on the type and complexity of the architecture and the quality of the training data) of images in which such faces have already been recognized, with information about the area occupied by them somehow recorded in association with that file. The methods of storing such data could be the subject of another article, so we won’t delve into those details here.

Fig. 1: Formatting data annotations (here in PASCAL VOC XML format) using a dog’s image as an example. In the case of labeling specific areas of images, a separate file like this must be prepared for each sample to describe its content. Source: ML course 2023, Natalia Potrykus
Another example could be data for a decision tree whose task is to determine a bank customer’s creditworthiness. To construct such a decision model based on customer information (gender, age, marital status, etc.), historical data about thousands of customers along with information about whether they had problems repaying their loans would be needed. Only then could a decision model be trained. Of course, there are various ways to deal with the problem of insufficient training data along with annotations, such as augmentation, synthetic generation, semi-supervised learning (we’ll get back to this), or even improving the model training process itself by selecting the most representative samples, called active learning. However, these methods do not always yield the desired results. Furthermore, as of the time of writing this article, no methods are known that can provide a certain solution to the choice of approach or guarantee their specific effectiveness.
It is much easier to obtain data for unsupervised learning, which is mainly used for data clustering, similarity identification, anomaly detection, and filling in missing data. In this case, sample labels are not needed. However, this approach is usually not suitable for classification or decision-making problems and has significant limitations in that mathematically modeled methods may not always cover real-world problems. They can work well for synthetic data augmentation, data clustering, similarity discovery, or anomaly detection.
The situation becomes even more complicated if you decide to configure the training parameters and architecture of a model (e.g., an artificial neural network) yourself. While there are Python libraries that offer pre-implemented and sometimes pre-trained models (e.g., PyTorch and TensorFlow), selecting the right architecture for your problem and adjusting hyperparameters (i.e., model characteristics declared in advance that do not change during training) remains a challenge. There are usually dozens of hyperparameters, each of which can significantly impact the network’s final performance. Even when choosing an advanced architecture that achieves near-perfect accuracy (close to 100%) on complex datasets according to scientific publications, the model may perform noticeably worse on your data if you choose the hyperparameters incorrectly.
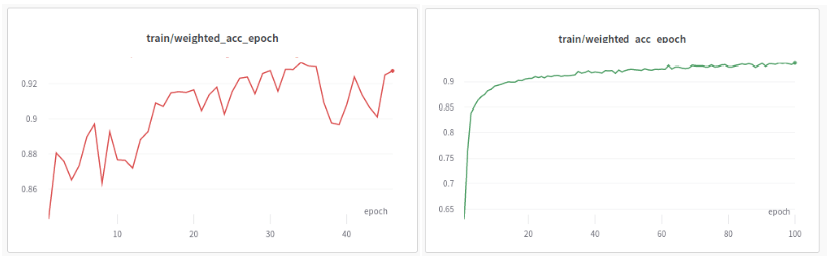
Fig. 2: Chart depicting the training progress of a model with the same architecture but different hyperparameters. Source: ML course 2023, Natalia Potrykus
Unfortunately, there is no ready-made remedy for solving this problem. There is no specific “recipe” for configuring architecture or training characteristics. The ability and intuition needed for this come from experience, and even then, some situations can still be challenging. If your team does not have experience working with artificial intelligence models, it is best to entrust the task of creating a dedicated neural network to specialists. Today, there are more and more companies on the market offering automation of business processes for corporations.
Training neural network models, which are currently the most popular choice for business process automation, is usually a lengthy process if you don’t have the necessary hardware resources. Such training is typically done on graphics processing units (GPUs), which allow for much better parallelization of matrix multiplication operations than is possible on central processing units (CPUs). Since training a neural network essentially involves multiple matrix multiplications, this can result in a significant speedup of the process. However, this requires access to the mentioned technical resources, either on-premises or in the cloud, which can generate additional costs. Additionally, technical proficiency in distributing processing tasks is required. Modern machine learning frameworks provide good support for utilizing GPU resources, but effective resource management is still necessary for the training process to run efficiently.
Let’s assume that we have successfully trained an appropriate neural network and deployed it in production. Does that mean we no longer need to worry about the ML module in our company? Far from it; this is just the beginning! The situation is similar to operating a production line in a factory—setting up a new line is likely a fantastic investment, but it requires constant monitoring and maintenance to perform its task for a long time. Sometimes, a component may need replacement, or bearings may need lubrication to maintain the system’s durability. At other times, a new component may need to be added as business needs change. With ML models, it’s a similar story. From the moment of deployment, you can certainly expect some time of satisfactory performance. However, it will depend greatly on changes in the operating environment. Let’s look at an example: we have a network that recognizes defective products based on camera images. The initial accuracy of the model is around 98% (meaning that about 98% of the products will be correctly classified). However, at some point, there is a need to replace the lighting in the production hall, and suddenly the accuracy drops to 65%! Such situations need to be addressed by involving artificial intelligence in business processes.
The solution to this problem is relatively simple: retrain the model with a new set of fresh data (in this case, images collected after the lighting change). However, collecting and annotating this data, repeating the training procedure, and deploying the model in an improved version are still required.
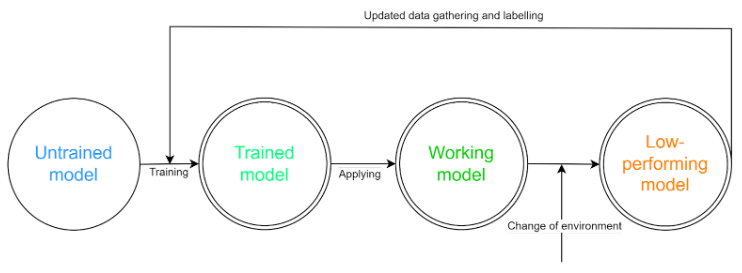
Fig. 3: Diagram illustrating the operational cycle of a model in a production environment. Source: ML course 2023, Natalia Potrykus
Some companies that specialize in machine learning development are aware of the issues faced by corporations and offer systems along with adapted models for monitoring their performance and detecting differences in incoming data. They may even support the retraining process in case of concept drift, which is precisely changes in the input samples being processed.
As we can see, while business process automation is becoming increasingly popular (and usually highly profitable), it must be carried out thoughtfully and consciously. However, with a well-executed process of implementing ML solutions into a company’s operations, incredible benefits can be expected—both in terms of efficiency and finances. Therefore, it’s worth expanding your knowledge in this area.

Responsible Software Development: How to Reduce Your Application’s Carbon Footprint?
Practical tips on how developers can actively reduce CO2 emissions by optimizing code, infrastructure, and application architecture.
Green ITInnovation

Green IT: How Technology Can Support Environmental Protection?
An introduction to the idea of Green IT – a strategy that combines technology with care for the planet.
Green ITInnovation

CI/CD + Terraform – How to Deploy Your Application on AWS? – Part 2
Learn about the possibilities of GitHub Actions - how to quickly deploy an application using GitHub Actions using AWS and Terraform technologies.
AdministrationProgramming