Helm for the Second Time – Versioning and Rollbacks for Your Application
We describe how to perform an update and rollback in Helm, how to flexibly overwrite values, and discover what templates are and how they work.
 Author:
Author:In today’s article, we continue the topic of machine learning. If you haven’t read our previous article on machine learning yet, we encourage you to do so. Today, we will learn a bit more about the approaches used in this field, their advantages and disadvantages, and also take a look at possible applications of some algorithms.
Machine learning is a broad field that can currently be divided into four subdomains:
– Supervised Learning
– Semi-Supervised Learning
– Unsupervised Learning
– Reinforcement Learning
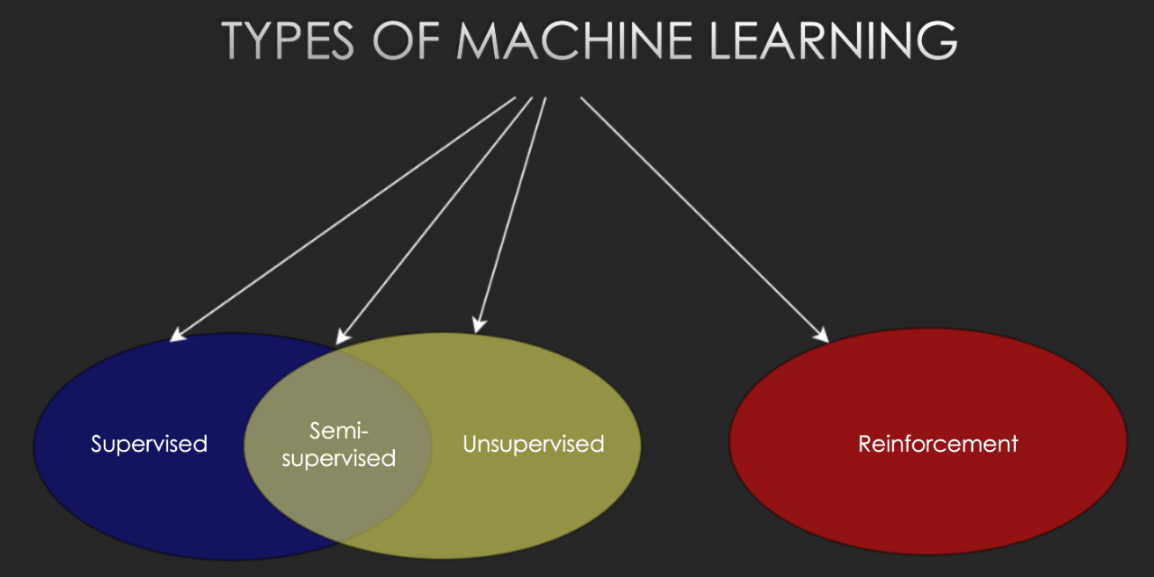
Figure 1: Division of machine learning into subdomains. Source: ML course 2023, Natalia Potrykus
This is a widely used approach in various industries, including automated industries. It includes methods such as creating decision trees or artificial neural networks for object recognition. Supervised learning is highly versatile and applicable across all industrial and research sectors, as it allows models to be customized for specific, well-defined tasks. For example:
– Classifying blood cell types.
– License plate recognition (often referred to as simply LPR)
One of the key characteristics, as well as drawbacks, of supervised learning is how models are trained. To adapt the architecture to a specific problem, large labeled datasets are required. This means that if you want a network to recognize faces in an image, training it on clean images with people is not enough. You must explicitly indicate which areas of the image are considered human faces. Initially, you need to provide the network with a large number of images with annotated faces. This additional file stores information about the location of the faces in a specific format. Only with a sufficient number of “trained” images can the network perform well.

Figure 2: Example of artificial neural network training process. Source: ML course 2023, Natalia Potrykus
This training method can be compared to how a child learns. If a parent points out and names birds during every walk – different species, in various environments and conditions – the child will eventually start recognizing those animals on their own. Moreover, they might even identify species they’ve never seen before if they recognize enough features previously attributed to birds.
The applications of unsupervised learning are less visible than supervised methods because, unlike supervised methods, we cannot specify a concrete task for the model or algorithm. Instead, we can gain insights into similarities between data, perform clustering, detect anomalies (data that differ significantly from the rest of the dataset), and sometimes even attempt to fill in missing data in certain structures. For example:
You have a dataset of a specific type of flowers, each of the 1000 specimens is described by:
– Petal length
– Petal width
– Center diameter
– Number of leaves.
You know that these flowers belong to 5 subspecies, each characterized by slightly different parameters (one subspecies typically has no leaves but long petals, while another may have leaves and very wide petals, etc.). You have no additional information, no labels, and you need to assign each sample to one of the subspecies.
In cases like this, supervised learning methods won’t help since you lack labeled data. Instead, you can successfully apply clustering, one of the most commonly used unsupervised learning approaches. Clustering involves examining data relationships and then grouping them into clusters (usually specifying the number of clusters in advance) based on these analyzed features. The results of such algorithms (like the popular K-means method, which produced the chart below) assign labels to the samples – groups them – which still does not answer our question about the specific flower species. However, once you have the data divided into 5 groups based on correlations between them, the problem becomes much simpler to solve. Instead of classifying each of the 1000 samples individually, you only need to assign the appropriate biological name to the entire groups, making the task more manageable.
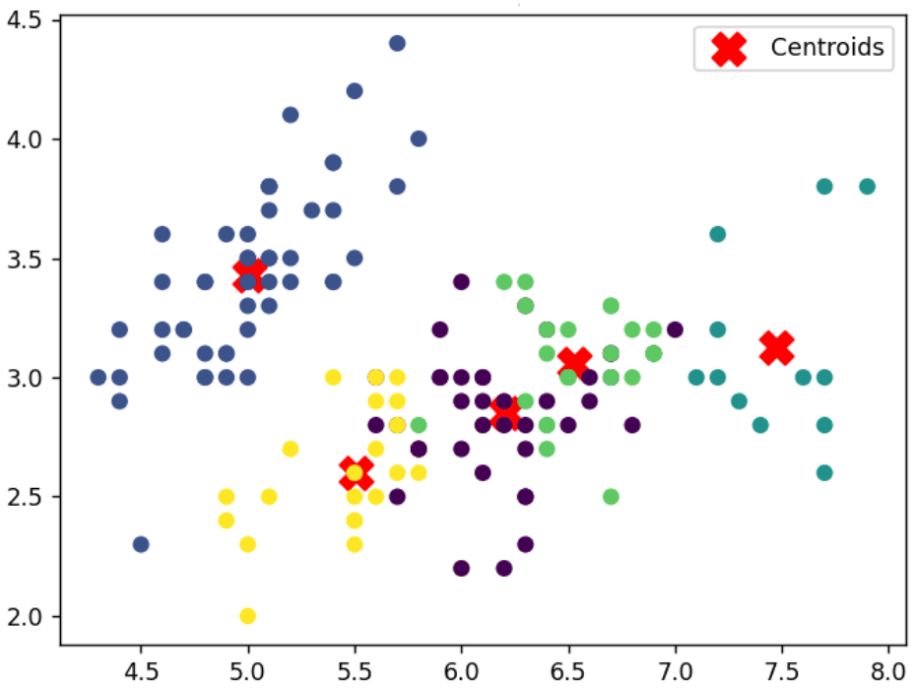
Figure 3: Visualization of clustering algorithm result. Source: ML course 2023, Natalia Potrykus
At first glance, this approach may seem to have more limited applications compared to supervised learning. For many fields, this is true. However, unsupervised learning does not have the limitation of recognizing known objects, patterns, or behaviors. In unsupervised learning, there are no such restrictions, and data can be continuously analyzed, and deviations from the norm can be successfully detected. This is particularly beneficial in the field of cybersecurity.
Semi-supervised learning is an attempt to reconcile the two previously discussed approaches and combine their benefits: the ability to set a specific goal for the model and the ability to have relatively few labeled data.
However, this approach often fails with unbalanced datasets, where the proportions of different classes are significantly unequal. The quality of the model is also heavily influenced by the representativeness of the initially labeled samples with respect to the entire dataset, and it’s often impossible to determine this in advance before training. All of these factors lead to greater uncertainty about the quality of the resulting network. Therefore, it’s important to keep this in mind when considering this approach, especially in situations where the algorithm operates on critical data (e.g., military or medical) or where inaccurate predictions could result in significant additional costs.
Reinforcement learning is a subdomain that, like supervised learning, requires data and some information about that data. However, instead of dealing with static samples and their labels, it typically deals with sequences – “moves” that an agent can make – and rewards received for each of those moves. Rewards can be positive or negative. During training, the agent explores vast numbers of paths (sequences of movements) and its goal is to find the path with the highest cumulative rewards.
This approach is applied in situations such as:
– Autonomous vehicles
– AI for computer games
– Complex bots for network attacks (as well as agents for detecting them).
Naturally, to be able to utilize the potential and all possibilities of those machine learning techniques, we need to understand how different kinds of data are actually processed – so next week we’ll focus on some most common approaches of data representations. Stay tuned!

Helm for the Second Time – Versioning and Rollbacks for Your Application
We describe how to perform an update and rollback in Helm, how to flexibly overwrite values, and discover what templates are and how they work.
AdministrationInnovation
Helm – How to Simplify Kubernetes Management?
It's worth knowing! What is Helm, how to use it, and how does it make using a Kubernetes cluster easier?
AdministrationInnovation

INNOKREA at Greentech Festival 2025® – how we won the green heart of Berlin
What does the future hold for green technologies, and how does our platform fit into the concept of recommerce? We report on our participation in the Greentech Festival in Berlin – see what we brought back from this inspiring event!
EventsGreen IT