Responsible Software Development: How to Reduce Your Application’s Carbon Footprint?
Practical tips on how developers can actively reduce CO2 emissions by optimizing code, infrastructure, and application architecture.
 Author:
Author:Today, we will continue our discussion on compilation and interpretation in programming languages. If you’re curious about the drawbacks of compiled languages in the modern developer world and how interpreters cater to modern needs, we invite you to read on!
Drawbacks of Compiled Languages
Why can compiled languages pose challenges for developers in the modern world? This is due, among other things, to:
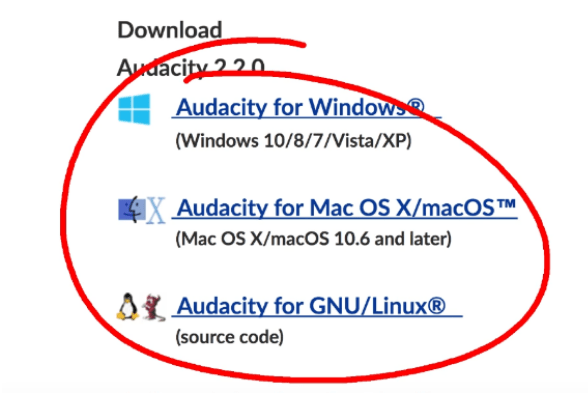
Figure 1 – Example of the Audacity program, which provides different installers for various operating systems.
Interpretation Process
So, what exactly is an interpreter? According to the definition provided by Jagiellonian University, it is a “program that reads and analyzes code written in one language and executes it on the fly.” It is a key component of a significant portion of scripting languages and languages compiled to bytecode.
An interpreter thus analyzes the source code of a program and immediately executes the analyzed portions. This process differs from compilation, where the input program (source code) is not executed but translated into executable machine code or intermediate code, which is then saved to a file. Only after this step can the user run the program. Execution of a program using an interpreter is slower and consumes more system resources than running compiled code. However, it can take relatively less time than the compilation and execution process. This is particularly crucial during code creation and testing, where the edit-interpret-debug cycle can often be significantly shorter than the edit-compile-run-debug cycle. Interpreting code is slower than running compiled code because the interpreter must first analyze each expression and then execute corresponding actions based on that analysis, whereas compiled code solely executes actions. In fully interpreted implementations, executing the same code fragment multiple times requires interpreting the same text multiple times.
Due to the ease of use of interpreted languages, they are still valuable despite their lower efficiency. Python’s efficiency lies in its rapid application development, which can be quite cost-effective from a business perspective, making it worth using even at the cost of application performance.
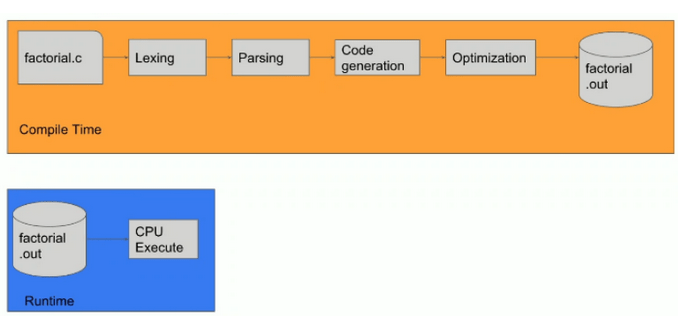
Figure 2 – Process of Compilation and Runtime Execution of Compiled Application, Source: Omer Iqbal, GeekcampSG.
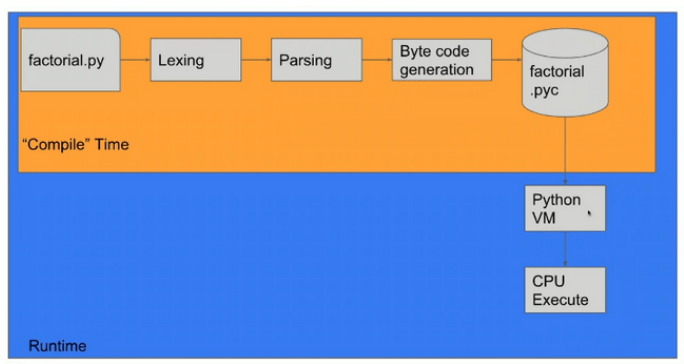
Figure 3 – Process of Interpretation, Source: Omer Iqbal, GeekcampSG.
As we can observe in the interpretation process, everything occurs at runtime, or during application execution. Therefore, applications in interpreted languages are often slower than those in compiled languages.
Interpretation Using Python and PVM
Most individuals working in the IT industry have encountered the Python language. It is intuitive and has a very low learning curve. However, have you ever wondered what happens after you type the “python” command in the terminal? When we enter “python3” or “python” in our terminal, we are actually launching the binary file of the interpreter, which is fully loaded into our computer’s memory. Python3 is essentially a compiled program, and when we write “python3 abc.py,” we are passing our code as an argument to it.

Figure 4 – Launching the Python Language Interpreter.
The program (interpreter) loaded into memory is divided into two sections: the Python Virtual Machine (PVM) and the compiler. Since we provide the Python file after the word “python” (e.g., hello.py), it becomes an argument of this program. The compiler will translate the Python source code from file.py to what is called bytecode (not machine code). The processor does not understand bytecode because it is not the same as machine code produced for a specific processor in a particular architecture. However, bytecode is also composed of zeros and ones, as it is a binary file. Bytecode is interpreted by the PVM, which can be thought of as a virtual processor. The Virtual Machine (PVM) takes bytecode instead of machine code and then calls it on a real processor by translating it into machine code. This process is illustrated below.
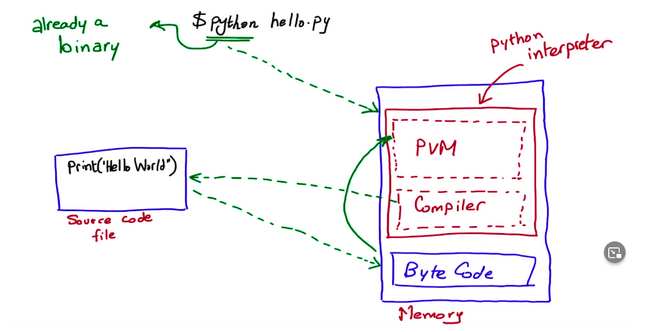
Figure 5 – Process of Interpretation in Python, Source: Afternerd YT.
In summary, the PVM component is responsible for handling all platforms on which the interpreter is available by translating bytecode into machine code. The compiler, on the other hand, focuses on translating source code into bytecode.
Example in the Python Language
Let’s now conduct a small experiment to understand how code interpretation works in the Python language.
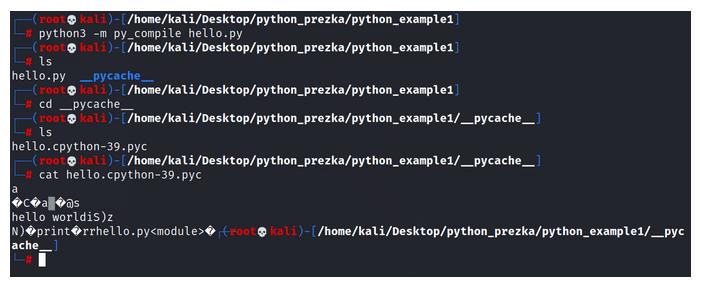
Figure 6 – Compilation to Bytecode of a Simple Hello World Program.
Let’s carry out the compilation of the program and generate the bytecode itself, which goes into the PVM. We can observe the created “pycache” folder containing a file with the extension “.pyc” that bears the interpreter name “cPython.” When displayed, the code appears obscured since it is bytecode, readable by PVM but not entirely comprehensible to humans.
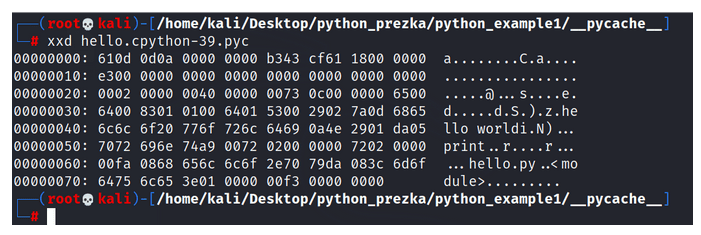
Figure 7 – Bytecode Displayed as a Binary File.
Upon entering the command “-m dis,” as shown in the figure below, we witness the translation of our bytecode into bytecode instructions in a human-readable form. If bytecode serves as machine code for PVM, then these instructions, in their comprehensible form, are akin to assembly language for PVM (virtual machine).
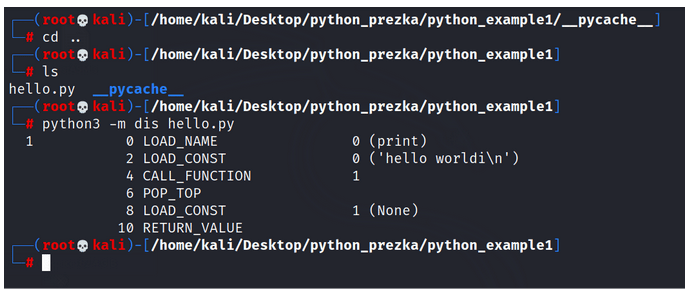
Figure 8 – Instructions Read from Bytecode.
The entire process of interpretation in Python can be represented as shown in the image below.
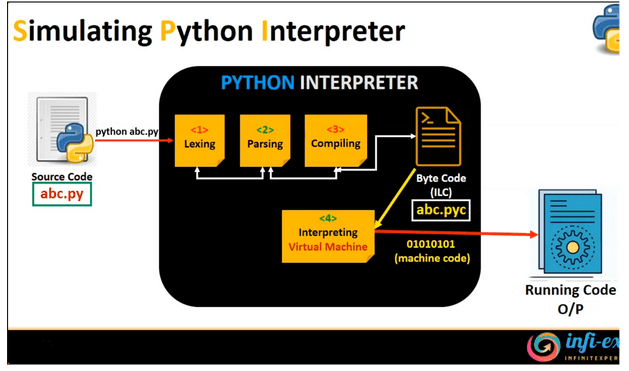
Figure 9 – Interpretation Process, Source: SNIPPET_MASTERY YT.
In summary, the process of interpretation consists of the following steps:
The compiler in Python resides within the interpreter, differing from, for example, Java.
Advantages and Disadvantages of Interpretation
Both approaches, namely compilation and interpretation, have their pros and cons. An evident advantage of interpreted languages is that anyone with an interpreter can run a program regardless of the platform. Developing an interpreter is significantly simpler than creating a compiler. The process of interpretation is usually faster than compilation since it does not optimize the code, although programs generated by an interpreter are less efficient compared to compiled ones. When it comes to drawbacks, it’s worth noting that due to the higher-level abstraction, an interpreter generates much more code. Adding a number to a variable can be represented by a single assembly instruction in compiled languages, while in an interpreter, it goes through the entire process. Furthermore, when comparing runtime performance (excluding compilation time in compiled languages), interpreted languages operate significantly slower.
Just-in-time Compiler
Regarding the significantly reduced runtime speed, modern interpreters provide us with a ready solution known as JIT, or just-in-time compiler.
The Just-In-Time (JIT) compiler is a component of the runtime environment that enhances the performance of interpreted applications by compiling bytecode into native machine code at runtime. Essentially, this means that a JIT-enabled interpreter detects “hot components” of code (repetitive and processor-intensive tasks), such as functions in loops. It generates machine code from them, substitutes the implementation, and executes the program using pure machine code for that specific code fragment.
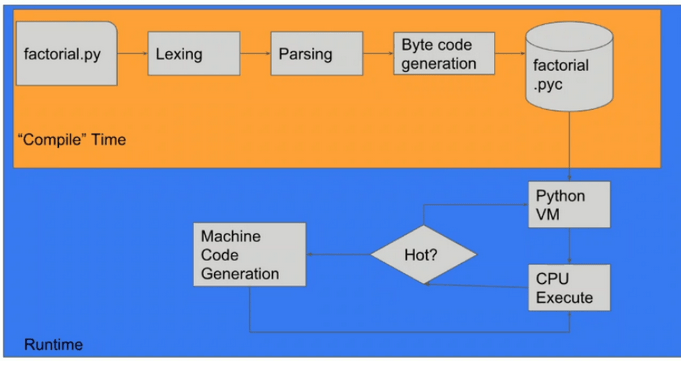
Figure 10 – Application of JIT in Python, Source: Omer Iqbal, GeekcampSG.
JIT also utilizes other optimization techniques, such as:
When Not to Use JIT?
Therefore, we try not to use JIT for tasks that are infrequently repeated, involve short and undemanding calculations, or are related to web programming. We can always measure the execution time of a specific function with and without JIT to determine if it’s worthwhile. Code optimized using a JIT compiler can be even thousands of times faster than the original code. There are interpreters that come with a built-in JIT compiler, and there are also those to which you can install a different compiler that supports JIT. There are many compilers available, and not all are suitable for all platforms. Examples of compilers that support JIT are PyPy, Numba, and Pyjion. It’s also necessary to check which version of Python a specific compiler requires.
Summary
In summary, it can be said that an interpreted language is designed with the user (programmer) in mind, rather than the computer, whereas languages like C or Assembler relate more to low-level operations executed on the processor. In compiled languages, we may have to wait longer for the generation of our executable file, but the final program is faster. A downside is the dependency on the operating system and architecture on which we perform operations. You can provide the executable file directly to the client, making the code more “private.” In interpreted languages, the client executes the sent source code on an interpreter unless someone applies code obfuscation to hinder reverse engineering and protect intellectual property, as seen in PHP ionCube. Code execution is slower in the runtime itself compared to a compiled language. The interpreter is independent of the operating system and architecture. Therefore, the choice depends on the specific case and business needs, as well as IT trends. We hope that the knowledge from our blog will contribute to better decisions in your companies.
Sources:

Responsible Software Development: How to Reduce Your Application’s Carbon Footprint?
Practical tips on how developers can actively reduce CO2 emissions by optimizing code, infrastructure, and application architecture.
Green ITInnovation

Green IT: How Technology Can Support Environmental Protection?
An introduction to the idea of Green IT – a strategy that combines technology with care for the planet.
Green ITInnovation

CI/CD + Terraform – How to Deploy Your Application on AWS? – Part 2
Learn about the possibilities of GitHub Actions - how to quickly deploy an application using GitHub Actions using AWS and Terraform technologies.
AdministrationProgramming