Helm for the Second Time – Versioning and Rollbacks for Your Application
We describe how to perform an update and rollback in Helm, how to flexibly overwrite values, and discover what templates are and how they work.
 Author:
Author:Today as Innokrea, we will tell you even more about supercomputers. If you’re interested in the technologies used in clusters or how giant supercomputers are cooled, you will find out all about it in our article. Enjoy reading!
Measuring computational power
The question arises: how do we measure the speed of a supercomputer? The parameter commonly used for this purpose is called FLOPS (Floating Point Operations Per Second). It is a widely used unit of computational power, representing the number of floating-point operations a computer can perform per second. It is commonly used to evaluate the performance of supercomputers, computing clusters, or graphics cards, for example.
GPU vs. CPU Dilemma
There are different approaches when it comes to building supercomputers. Typically, each computer has its GPU to support computations, although not always. GPU computing refers to the use of a graphics processing unit (GPU) as a coprocessor to accelerate CPU computations.
GPU systems are best suited for repetitive and highly parallel computational tasks where the computations are independent of each other, such as textures in games (where each object is moved parallelly by a certain vector when the camera moves). In addition to video rendering, GPU systems are used in machine learning, financial simulations, and many other types of scientific computations.
Therefore, GPUs accelerate applications running on the processor by offloading certain computationally intensive and time-consuming parts of the code. The rest of the application still runs on the processor. From the user’s perspective, the application runs faster because it utilizes the massively parallel processing power of the GPU to increase performance. This is known as hybrid processing.
It’s worth noting that a processor usually consists of four to eight CPU cores, while a GPU consists of hundreds of smaller cores. Also, remember that the parallel architecture of GPUs provides truly high computational performance but only for problems that can be inherently divided into parallel subproblems. The problem should also be sufficiently large because distributing small problems may paradoxically increase execution time due to communication overhead.
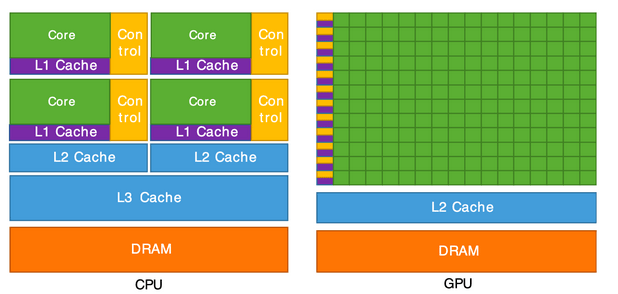
Figure 1: CPU vs. GPU comparison – source: Cornell University.
Available Technologies
There are many technologies that allow for the utilization of additional GPU power or supercomputer nodes. However, we will mention two of them – CUDA and MPI.
CUDA is a parallel computing platform created by NVIDIA. With over 20 million downloads to date, CUDA helps programmers accelerate their applications by leveraging GPU power. It enables parallel processing by dividing the computational task into thousands of smaller “threads” executed independently. The CPU is also involved in the computations, but some tasks can be delegated to the GPU by passing instructions. When the GPU completes the assigned work, the results are passed back to the CPU for application utilization. CUDA is used, for example, in machine learning in various fields such as natural language processing or image recognition.
MPI, on the other hand, is a standard for programming distributed computers that enables the cooperation of multiple processes in problem-solving. It provides a set of library functions and syntax for message passing between processes in parallel programs, making it a popular tool in high-performance applications such as supercomputers or clusters. MPI was created with three main goals: providing high quality, scalability, and portability. It is currently a widely used model in computer clusters and supercomputers. The first version of the standard was published in May 1994. The MPI standard is typically implemented as libraries that can be used in programs developed in various programming languages such as C, C++, Ada, or Fortran. There is also the possibility of using MPI in Python (PyMPI).

Figure 2: Fragment of C code using MPI.
Data Center Cooling
There are two main methods of cooling data centers or supercomputers:
During the construction of a data center, proper placement of rack cabinets should also be considered to create hot and cold aisles. This ensures efficient airflow management.

Figure 3: Visualization of heat dissipation in a data center, source: 42u.com.

Figure 4: Photo showing liquid cooling in a high-performance system, source: CoolIT Systems.
For the world’s largest supercomputers that produce massive amounts of heat, equally gigantic water tanks are needed for cooling. These tanks have capacities measured in hundreds of thousands or even millions of liters. They are usually located in specially designed rooms or outside the building. Supporting devices such as heat exchangers and pumps are present, and the entire system is filled with a range of sensors to monitor its condition and operation. Alarm systems are also in place to warn of failures or improper functioning.

Figure 5: Cooling of the Stampede supercomputer in Texas, 3.8 million liters of water, source: Quora.
We hope that this article was interesting to you. In the next part about supercomputers, instead of focusing on programming or design aspects, we will talk about networks in supercomputers, which are built differently than standard corporate networks or even data centers.
Sources:

Helm for the Second Time – Versioning and Rollbacks for Your Application
We describe how to perform an update and rollback in Helm, how to flexibly overwrite values, and discover what templates are and how they work.
AdministrationInnovation
Helm – How to Simplify Kubernetes Management?
It's worth knowing! What is Helm, how to use it, and how does it make using a Kubernetes cluster easier?
AdministrationInnovation

INNOKREA at Greentech Festival 2025® – how we won the green heart of Berlin
What does the future hold for green technologies, and how does our platform fit into the concept of recommerce? We report on our participation in the Greentech Festival in Berlin – see what we brought back from this inspiring event!
EventsGreen IT